Super vs Dust - How I tested their Enterprise Search quality
I tested the 2 best Enterprise Search tools on the market on search quality, speed, accuracy and which features differ from each other

Super and Dust are both AI-powered enterprise search tools that connect to your company's data sources and let you ask questions to find information across all your tools.
Both use RAG and LLMs to search your company knowledge, but they differ significantly in setup complexity, response speed, and how your team actually uses them.
I tested both by connecting them to
- Slack and Google Drive
- Asking 15 questions each
- Tracking answer quality, speed, and formatting.
Beyond that, this article covers data sources, setup experience, side-by-side testing results across all question types, unique features each tool offers, and which one actually makes sense for daily use.
Pricing
Super offers a free 3 week trial pilot with white-gloved onboarding with your dedicated Slack channel with the team for feedback and quick turnaround. (Talk to sales here).
Dust has a 14-day self-serve trial.
On pricing,
- Dust runs $34 per month per user
- Super costs $20 per month per user (and $15 on the yearly subscription)
Conclusion: Super comes out to be 33-50% cheaper than Dust
How I tested search accuracy
I connected both tools to the same 2 sources (Slack and Google Drive), created a 4-point grading system, asked them 15 questions across different levels of difficulty.
Judgement criteria and grading system
2 factors determine the quality of an enterprise search tool
- Answer accuracy - The core function is helping you find information accurately. If they hallucinate facts, they're more destructive than helpful in terms of business impact.
- Response time - If one tool takes 30 seconds vs. 30 mins, which would you actually use daily? Fast tools get adopted. Slow tools get abandoned because it's faster to search yourself.
And from it, I did a 4-point rating system
- 4 - Fully accurate: Answer's correct, comprehensive, cited, well-formatted
- 3 - Accurate with minor blindspots: The answer is accurate while omitting a few things (1 value prop out of 5, etc.)
- 2 - Partly Correct: The answer has some correct fragments mixed with some incorrect/outdated information
- 1 - Incorrect: The answer is false or contradicts sources.
Types of questions
- Simple queries - Finding specific pieces of information verbatim from your knowledge sources
- Medium broad knowledge - Understanding company context and semantically connecting different information sources
- Complex step-by-step queries - Planning research, collecting data points, synthesizing them, and deriving an answer
- Meta queries - Understanding metadata (like "Who's the most active person in our team Slack?")
- Data queries - Testing retrieval accuracy of hard facts for reporting or analysis
This is how my testing sheet looked
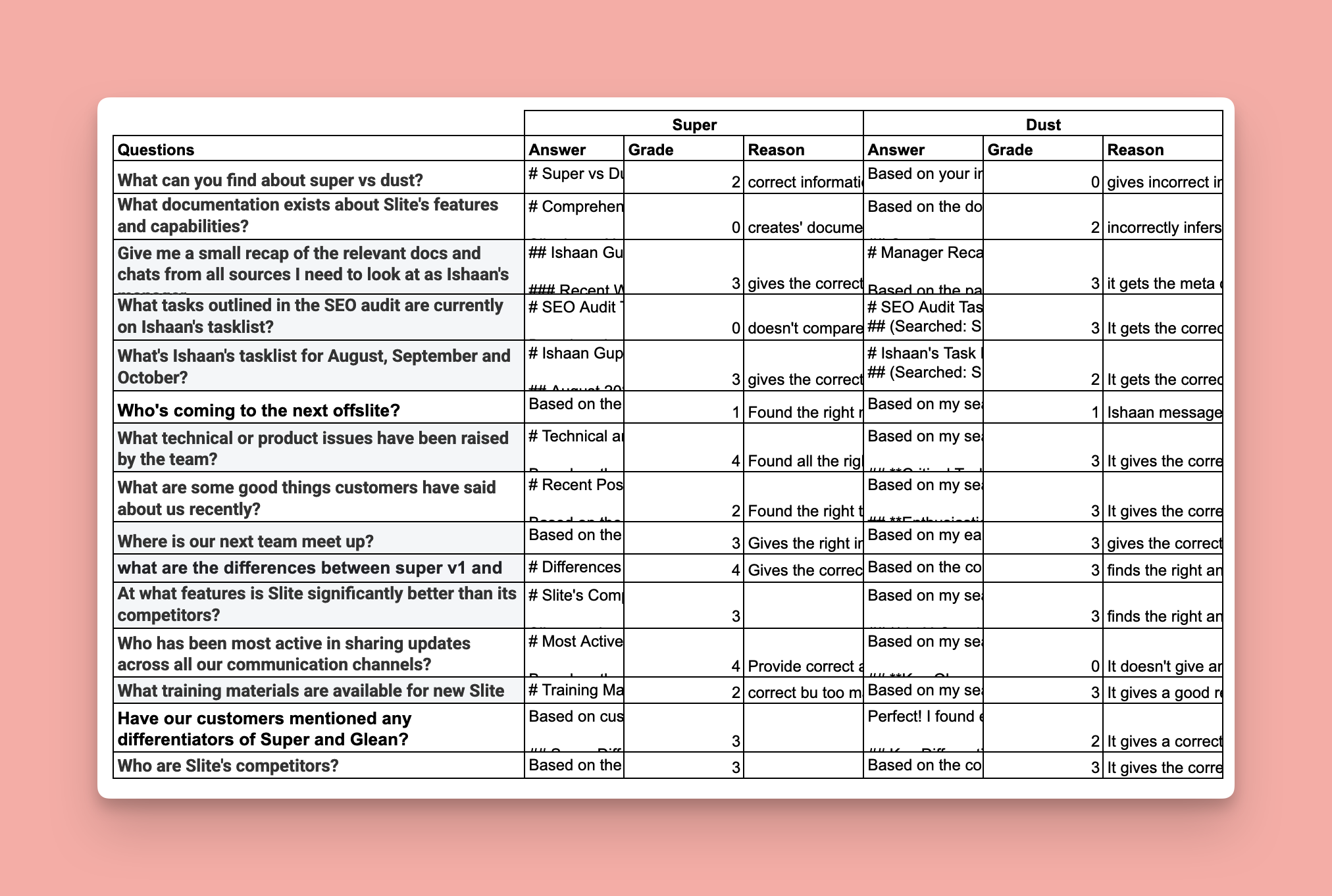
Side-by-side results
This is the recap of their times, and how they performed on each question:
| # | Question | Super Time | Super Performance | Dust Time | Dust Performance |
|---|---|---|---|---|---|
| Q1 | What can you find about Super vs Dust? | 26s | Found the right info but buried in fluff | 21s | Gave incorrect info from Drive |
| Q2 | What documentation exists about Slite's features? | 28s | Delivered comprehensive documentation with proper links | 22s | Found docs but incorrectly inferred Slack messages as documentation |
| Q3 | Give me a recap of relevant docs and chats as Ishaan's manager | 27s | Flawless response with complete context | 54s | Got meta context from Drive metadata and Slack activity |
| Q4 | What tasks from the SEO audit are on Ishaan's tasklist? | 35s | Accurate comparison with proper cross-referencing | 42s | Compared sources correctly and gave useful analysis |
| Q5 | What's Ishaan's tasklist for August, September and October? | 38s | Perfect answer pulling from both sources | 59s | Got Slack info but missed needed Drive doc |
| Q6 | Who's coming to the next offslite? | 14s | Found right thread with accurate RSVP counts | 57s | Counted duplicate RSVPs as separate people |
| Q7 | What technical or product issues have been raised? | 40s | Comprehensive answer with proper depth | 29s | Correct info with insights on what's "low hanging" |
| Q8 | What are some good things customers have said recently? | 26s | Complete feedback properly segmented by theme | 36s | Correct info segmented by type |
| Q9 | Where is our next team meet up? | 26s | Right info, concise answer | 21s | Correct info with some fluff |
| Q10 | What are the differences between Super V1 and Super V2? | 34s | Flawless answer, properly cited with technical depth | 33s | Right answer with comparison table |
| Q11 | At what features is Slite significantly better than competitors? | 33s | Comprehensive correct answer with competitive positioning | 51s | Right answer, well formatted |
| Q12 | Who has been most active sharing updates across channels? | 32s | Perfect answer with platform-specific activity details | 39s | No deterministic answer despite invoking both tools |
| Q13 | What training materials are available for new Slite users? | 20s | Clean response with all official docs and proper links | 32s | Good response with the 4 official docs |
| Q14 | Have customers mentioned differentiators of Super and Glean? | 25s | Accurate answer with customer feedback | 34s | Correct with needed facts but included irrelevant info |
| Q15 | Who are Slite's competitors? | 17s | Excellent answer with competitive landscape | 32s | Correct answer with comparison table |
Testing conclusion
Accuracy - Tie
Both scored an avg. 2.5/4 on quality and were tied to the last decimal point (2.467 for each). Both of them gave correct answers by citing the correct sources and didn't hallucinate false information. Both missed a few questions but overall, I'd deem both extremely reliable for finding accurate company information.
Response time → Super wins
Super consistently responded faster than Dust (27.7s avg vs Dust's 37.5s avg). Dust took especially long with responses with Slack because they retrieve Slack info via an MCP.
While the above 2 criterion cover core functionality and are essential for adoption, there's 2 more things I observed during the test.
Formatting → Dust wins
Dust's responses were well formatted to the nature of the answer. It felt more skimmable and suited to the nature of actual work documentation.

Citations → Super wins
Super had much better inline citations. For every substantial point, Super cited it and upon hovering, briefly explains why the source was cited the way it was. Dust cited its sources but you'd have to redirect to the source to see where it got its information from.
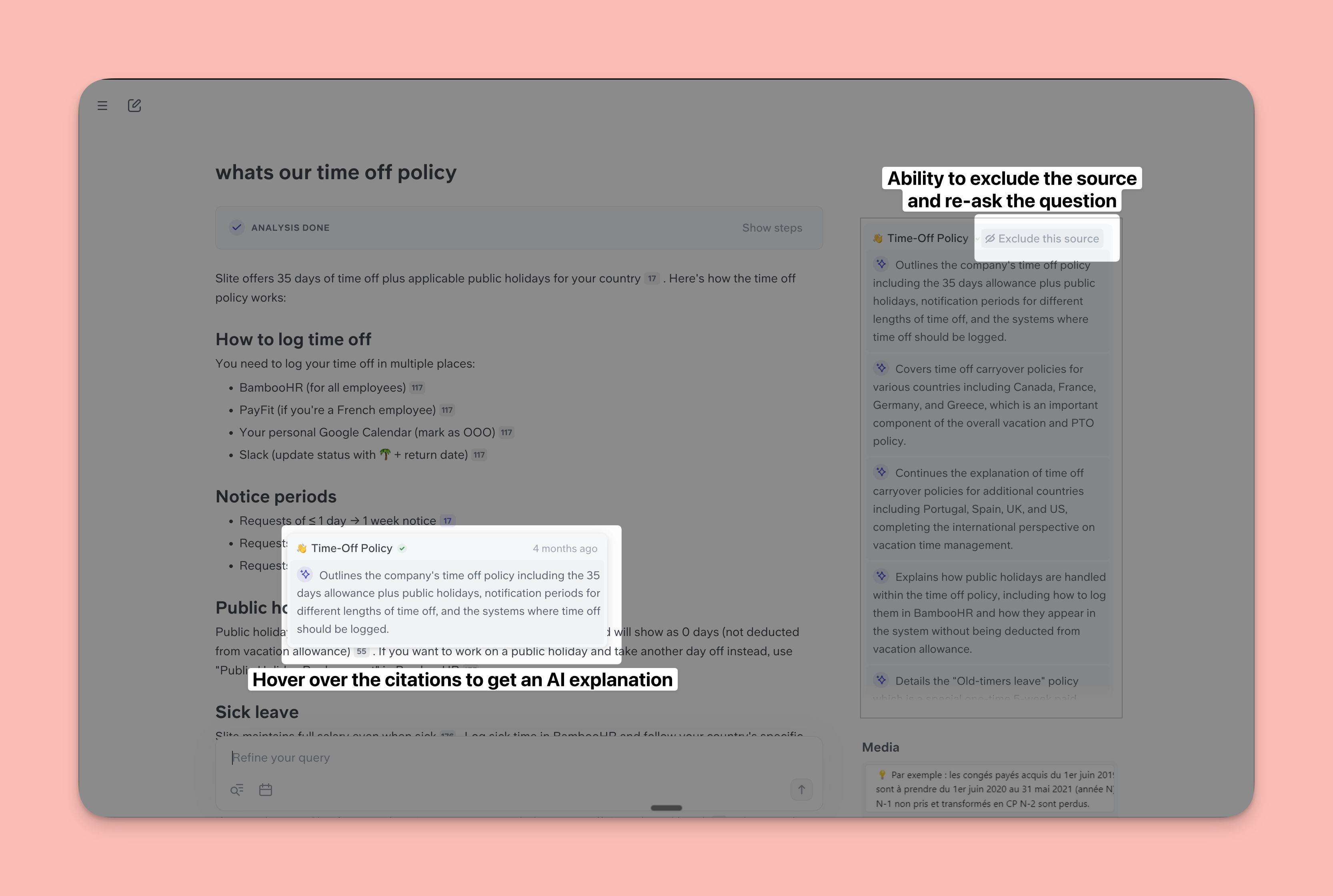
Moreover, in Super, if an outdated source gets cited, you have to option to exclude it in a single-click and re-ask the question. No similar specific source exclusion exists for Dust,
Overall testing conclusion,
Super's 1.5-2x faster than Dust while being equally accurate. Dust's responses have a better format, while Super's responses have better citations.
Data sources
The offering of data sources can make or break the buying decision.
- Native integrations: Super has 13 native source integrations while Dust only has 9.
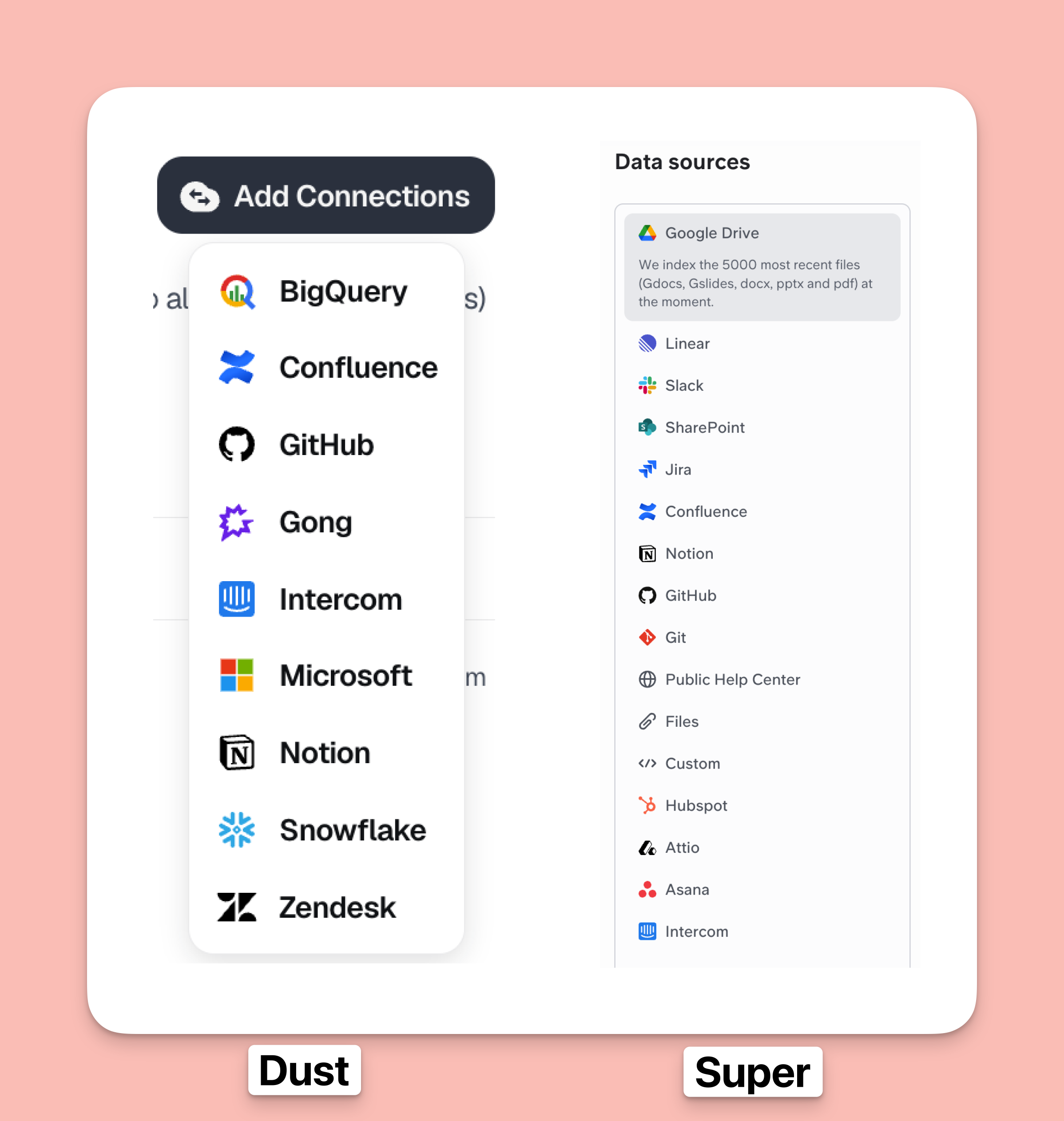
- Public website indexation: Both tools let you connect public websites as sources.
- MCP access: Dust supports connecting to other tools via MCP but Super doesn't. As of writing this article, MCP support for Super is coming soon.
- For unsupported apps: You can build your own connection using Super's custom source documentation.
To conclude,
Super wins because it offers 13 deep native integrations while Dust offers only 9. Dust supports MCP connections while Super lets you build custom sources for unsupported apps.
Setup and permissions management
In this section I go through their setup differences, nuances in how they handle source indexation, and how easy they are to set up and get running.
User permissions management
Dust offers three roles:
- Admin - can manage connections, manage users, and other subscription details
- Builder - can index specific data and create custom apps
- Member - can only use agents built by admins/builders
Super has two roles:
- Admins - can manage users, data sources, subscription details
- Members - can access data and use the tool.
When it comes to rolling them out team-wide, both tools let you add people easily, but Super lets you invite directly from Google or Slack, which is cleaner.
Connecting and setting up data sources
Both have simple UIs for connecting sources. However, Super indexes and syncs data sources faster. For instance, I tried connecting Github to both tools for the test and Super did it in under 30 minutes with clear progress update. Dust was stuck for 12 hours with no status updates.
There's another big difference - Dust divides its data sources into public and private spaces. Data indexed in public spaces can be accessed by everyone, or a specific set of people. And then, there's private spaces where you can index data that no one else in your team can see. While it can feel complex, Dust users can overall enjoy more granularity over how they're indexing sources and who they're sharing it with in their teams.
Ease of setup
Dust's interface feels more complex while Super's interface is straightforward enough that anyone can use it without help docs.
Because of this complexity, Dust requires months of implementation. Our sales team regularly hears from leads that Super takes 1-2 weeks while Dust can span months.
If I were setting up Dust, I'd be wary about getting permissions right across private/public spaces and admin/builder/user roles.
To conclude,
Super is easier to setup while Dust's setup is complex and can take weeks. It's because Dust offers more granular control over data sources and user roles.
Entry points
What's similar
Both have web apps and chrome extensions. Super did slightly better at gathering context from external webpages.
What's different
You can use Super right in
- Slack by typing "@Super"
- Web companion on any page. Super contextual buttons let you inject buttons on specific pages that retrieve context and perform specific actions. For instance, the Intercom button grabs the entire conversation context, generates a response in your tone based on your sources, and pastes it where you need it. This saves massive amounts of time.
Hence,
Super wins against Dust here because it has 2 more entry points for daily usage
Agents vs Assistants
Have you used ChatGPT custom bots or Claude projects before? They're both ways to build custom bots on pre-loaded context with specific instructions to cater to specific use cases.
Similarly, you have Assistants in Super and Agents in Dust. While they can both be used for custom use cases, they differ quite a lot in capabilities.
Dust Agent's unique differentiators
- Specific model access - You can choose your favorite GenAI model like Claude Sonnet 4.5, GPT 5, or Mistral models. You can read more about their model offerings here.
- Multi-modal GenAI capabilities - You can use image generation or artefact generation capabilities (via Frames) right within Dust.
- Auto-run triggers - You can pick triggers or times for your agent to auto-run.
- Agentic actions in external apps - You can let Dust agents take external actions like updating details in your CRM, etc.
Super Assistant's unique differentiators
- AI-assisted creation - You can create assistants using AI by just explaining what you need.
- Auto-exclude outdated data - You can specify time-frames for knowledge sources so your assistant automatically excludes information that gets outdated with time.
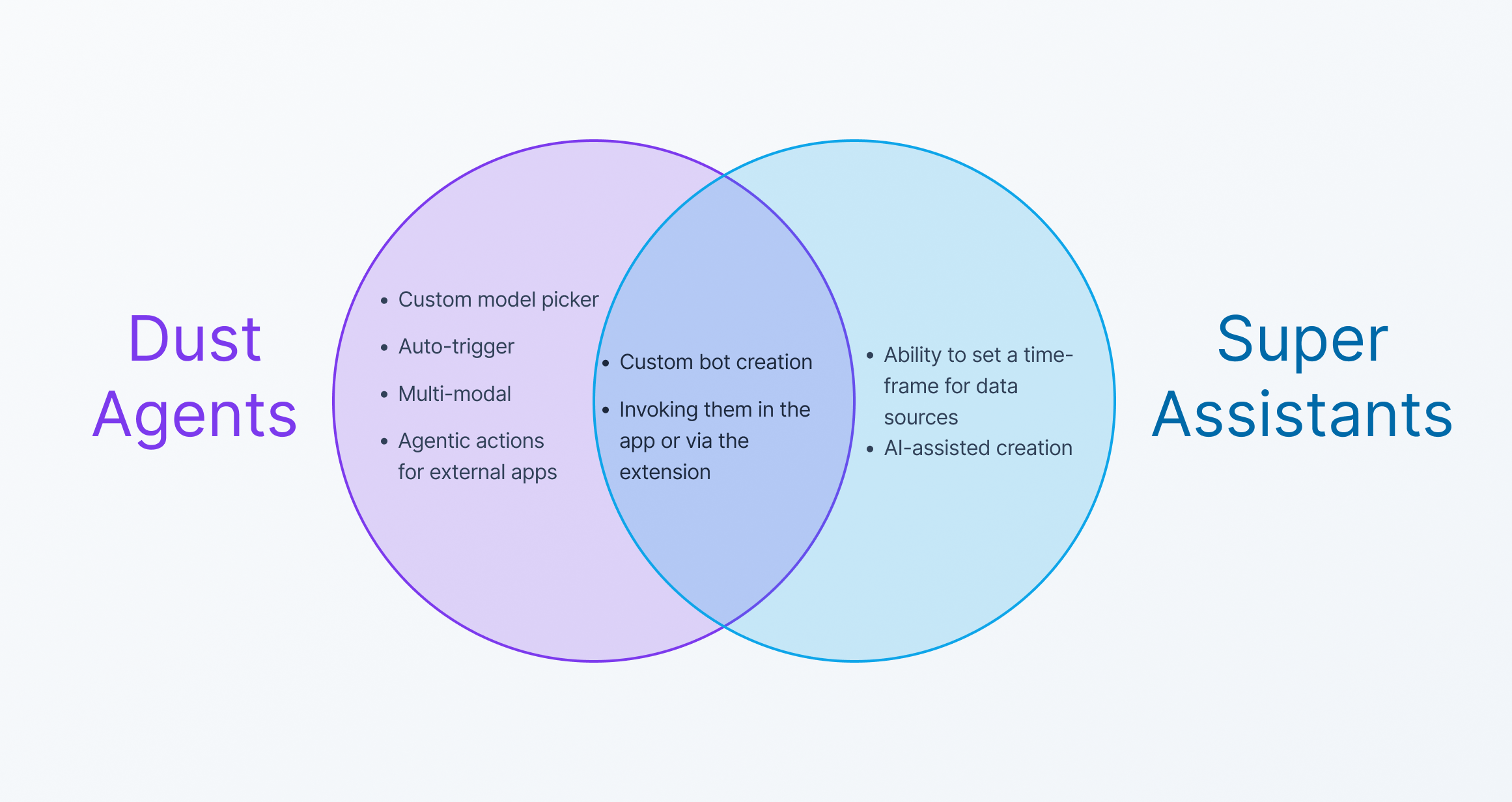
Hence,
Dust has better Agents with agentic and multi-modal capabilities while Super's assistants excel in text-generation capabilities.
Unique features
Beyond enterprise search and custom bots, each Dust and Super have more features that are truly unique to each. For instance,
Dust has
- Apps
Super has
- Bulk Mode
- Digests
- Contextual button
Let's go through all 4 of them one by one.
Dust Apps
You can build internal apps in Dust with input blocks and custom workflows based on your company data.

This could be useful for folks who build workflows with n8n or Zapier and aren't afraid of API docs.
However, it's too complex for 95%+ of users.
I'm a non-coding tech enthusiast who can do LLM prompting and basic workflows, but Dust apps aren't for people like me. This feature needs actual developers on your team.
Super Digests
Digests are automated AI-powered reports that pull from multiple sources and deliver regular updates without manual effort. You set your data sources and format, then get reports periodically via Slack or email. It's automated several reports in our team.
Previously, our AE manually summarized her weekly deals every Monday. Now Super does it automatically and sends it to leadership before we start our week. Digests differ from Assistants because they're automated reports while Assistants need specific questions.
Super Bulk Mode
Bulk Mode lets you paste 10-1000 questions and get answers in one batch instead of processing them one by one.
I tested it with 20 questions that would've taken hours to answer manually by digging through docs and following up with the product team. It can actually handle 100s at once, making it a legit game changer for RFPs or security questionnaires where you have 100s of questions on a deadline.
Super Contextual Button
Contextual buttons are AI-powered interface elements embedded in web apps that provide help without switching platforms.
The button reads what's on the page (account details, conversation history), adds context from your connected sources, then executes predefined actions like summarizing conversations, surfacing notes, drafting replies, finding similar issues, or identifying subject matter experts.
Final verdict
Before I get into my final verdict, here's a quick recap of the main findings
- Setup
- Dust requires heavy setup (weeks to months) with fewer sources and entry points.
- Super works out of the box in hours with more use cases that are immediately useful.
- Features and capabilities
- Dust offers more model variety and can help dev teams build internal apps.
- Super offers a consistent experience with features that can be used for every department like bulk mode, digests, contextual buttons, etc.
- Head-to-head comparison on response quality
- Both scored 2.5/4 on answer quality
- Super averaged 27.7 seconds vs Dust's 37.5 seconds
So, what do you make of this?
I can explain it with the analogy of Android vs iOS.
Android lets you peak under the hood, in fact, it wants you to make the tweaks and configure it exactly how you want it - even if the end experience is a bit wonky at times. iOS lets you do less, it's opinionated, and everything just works flawlessly. Regardless of the OS you pick, the core functionality of browsing the web, making phone calls, etc. remains the same. Your enthusiastic teenager might choose Android so he can tinker with it. But most people would be better off with iOS because Apple nails the obvious and makes it just that simple.
That said, Dust is Android and Super is iOS.
Dust's maximum ROI is achieved when you have a few internal product experts who are willing to do the groundwork of making internal apps on Dust. You need internal champions with technical skills to ensure you make the most of that $34 subscription. Otherwise you're wasting the $15-20 markup on each seat.
Super's maximum ROI is achieved out of the box. Companies know what to do with it, all the use cases are useful for all departments, and it's accessible to each user - the technical and non-technical alike.

Ishaan Gupta
Ishaan tracks the AI knowledge work shift for Slite and Super. He reads too much, argues with too many takes, and tries to find the words for things before they have words, e.g. knowledge drift, context graphs, workslop, and whatever the next term will be. When he's not writing, he's probably building AI agents to do it for him.
Ready to supercharge your workflow?
Connect your tools and start getting instant answers.
We've been building solutions for knowledge sharing and better work since 2016.