How do MCPs compare against a dedicated company search agent?
Same questions, same data, three setups. Here's what we found about speed, accuracy, and where each approach actually wins.

There's a recurring assumption in the current wave of AI tooling discourse: if you have a sufficiently capable model and connect it to your company tools' MCPs, the retrieval problem is solved. The model will figure out where to look, what to pull, and how to synthesize it. The reasoning layer, in this view, is the bottleneck. The retrieval layer is just plumbing.
We tested this assumption.
At Super, we build a retrieval engine for enterprise knowledge, the kind of system that connects to a company's Slack, Linear, CRM, support tools, and documents, then answers questions across all of them.
With the Model Context Protocol becoming the universal standard for connecting AI models to external tools (97 million monthly SDK downloads, backed by Anthropic, OpenAI, Google, and Microsoft as of late 2025), a straightforward question kept surfacing
Could a team skip a purpose-built retrieval layer entirely and just wire Claude to their tools via MCP? Has Anthropic killed our startup?
We designed a benchmark to find out.
The methodology
We compared three configurations, all querying the same company data (ours):
- Super - our product, connected to Slack, Linear, Attio, Intercom, and Slite for this test.
- Claude Code with MCPs - Claude with five MCP integrations: Linear, Attio, Slack, Intercom, and Slite. The same data sources a team would realistically wire up.
- Claude Code with Super - Claude using Super's MCP as its single data source. Think of this as a hybrid: Claude's reasoning on top of our search layer, instead of individual tool connections.
Same questions. Same data. Same person rating the answers.
One thing to flag upfront: we ran this on our own company data, and a Super team member did the rating blindfolded.
What we asked
We ran the kinds of queries a real team member would ask on any given Tuesday:
- Simple lookups: "What's our Stripe discount for annual plans?", "What's Slite's registered address?", "What are our SLAs?"
- People-related queries: "What has Jason achieved in July 2025?", "List the main features Charley worked on, one per month"
- Complex synthesis: "Generate a changelog from tickets closed in Linear and merged PRs last week, only about Super"
- Broad knowledge: "Give a 360 overview of Frontify" (a customer account)
Some of these need a single fact pulled from one source. Others need the AI to stitch together information from three or four tools and make sense of it. That range matters, because the gap between these setups changes dramatically depending on what you're asking.
How we rated
Every answer got a score from 0 to 4:
- 0 - Given for completely incorrect answers that misinterpreted the question, gave the wrong information, or hallucinated.
- 1 - For answers that were based on mixed data from correct sources and outdated sources
- 2 - For answers that were partially correct, but could be risky for data-related queries.
- 3 - For nearly perfect answers in terms of facts.
- 4 - For answers that were not only factually correct, but well-formatted, and added related context.
The results
Upfront, here is what we observed
- Our dedicated company search answered 2.6x faster
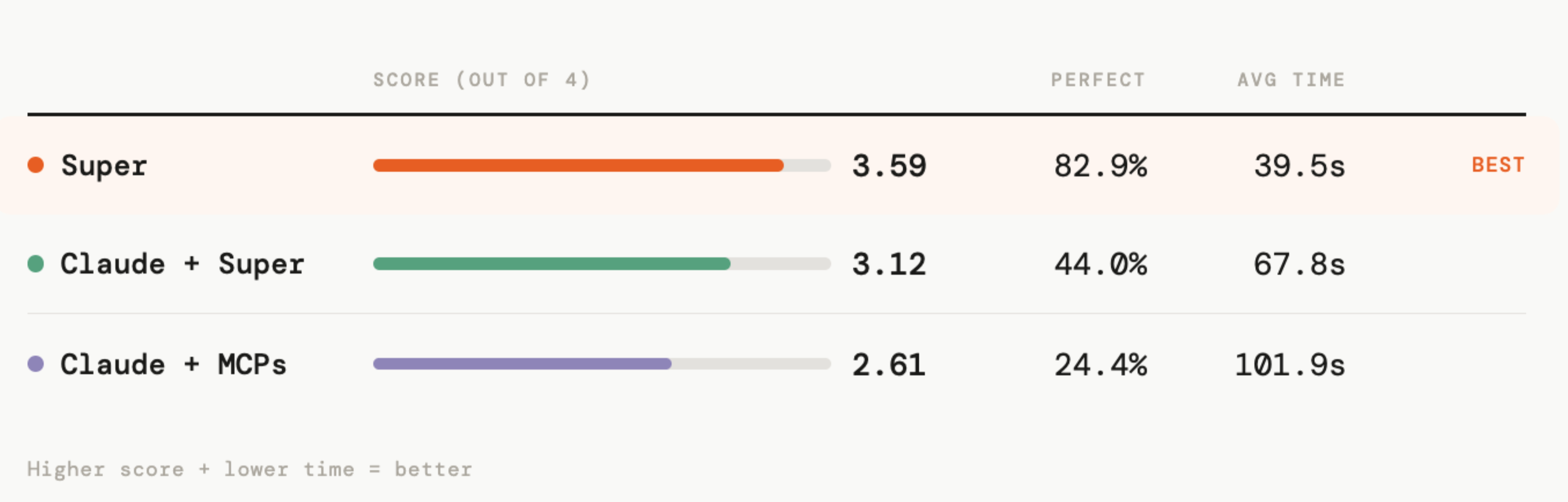
- It gives stellar answers (exhaustive and fully complete) 83% of the times, versus 25% with Claude.
- Simple connectors gave wrong or poor answers in 31% of the cases (vs 9% for Super)
Speed
For simple lookups, the gap was modest and ignorable.
But for anything requiring multiple sources, Super was 1.5-8x faster. Across all 41 questions, Claude with MCPs averaged 2.6x slower than Super. Claude with Super averaged 1.7x slower.
| Query type | Super | Claude + MCPs | Claude + Super |
|---|---|---|---|
| Simple lookup | 16s avg (9-31s) | 55s avg (36-92s) | 32s avg (20-45s) |
| Broad knowledge | 76s avg (46-123s) | 116s avg (94-142s) | 134s avg (76-202s) |
| Complex synthesis | 49s avg (15-132s) | 119s avg (35-282s) | 83s avg (19-195s) |
| Data queries | 32s avg (14-63s) | 121s avg (49-240s) | 50s avg (35-87s) |
The widest gap came up on a 12-month feature breakdown, where Super took 35 seconds and Claude with MCPs took 282 seconds.
The reason is architectural. Claude with MCPs calls each tool sequentially, one after another. A question like "What did Charley work on across 12 months?" triggers eight or more separate searches across four integrations. Each call adds latency. When one tool throws an error (Intercom cascade errors alone added roughly 30 seconds in some runs), the entire chain stalls.
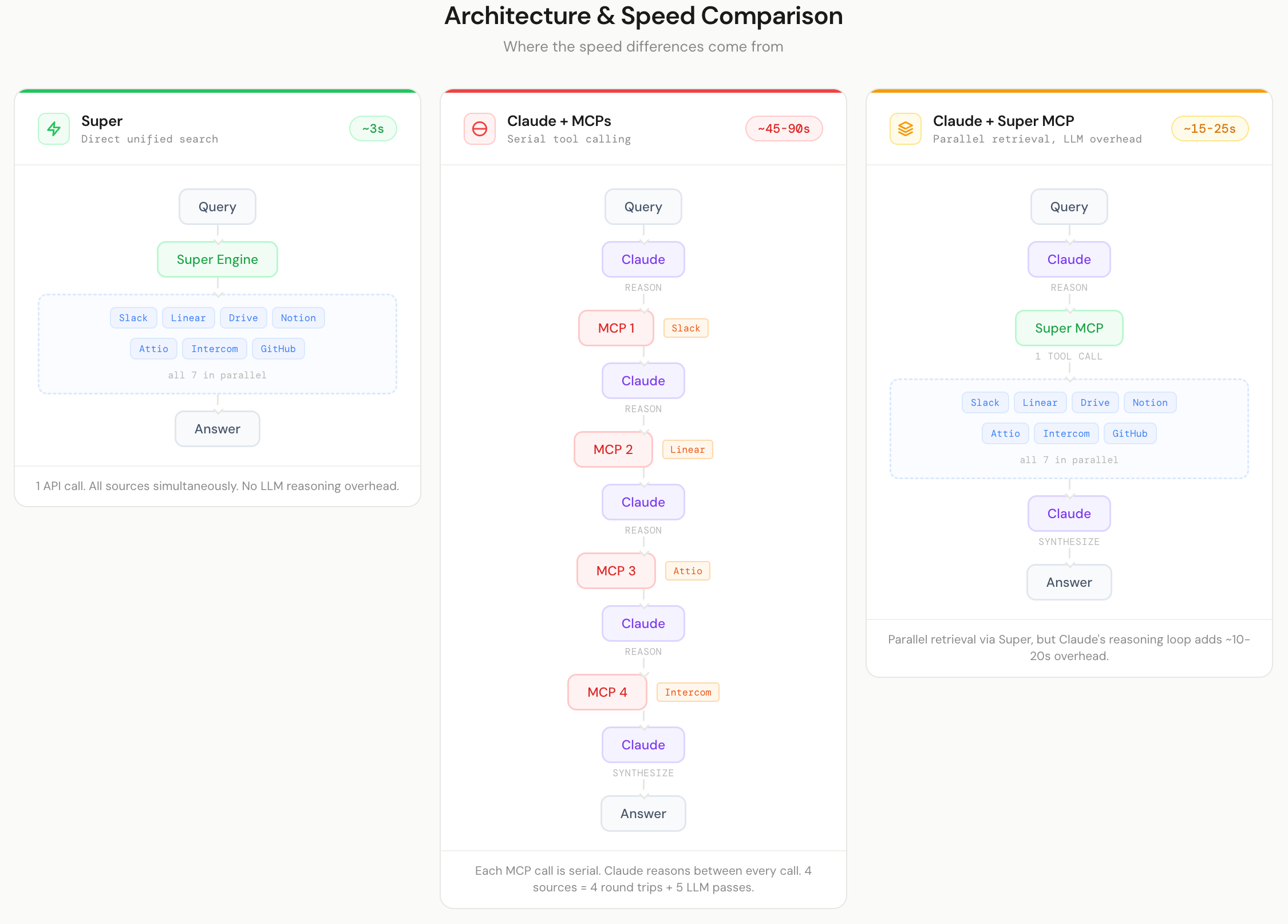
This is not a problem unique to our test. Research on parallel versus serial tool calling consistently shows the latency difference is structural. Relace documented a 4x reduction in end-to-end latency by parallelizing tool calls while retaining accuracy. The fundamental issue is that serial tool calling scales linearly with the number of sources queried, while parallel retrieval keeps latency roughly constant regardless of source count.
The MCP ecosystem compounds this. A DEV Community analysis described the current state as a "Wild West of broken implementations,"documenting endpoint discovery failures and retry logic entering infinite loops.
Super queries all sources in parallel with a single call. The difference purely comes down to how the retrieval layer is architected.
Accuracy
For simple factual queries, Super still led but the gap was smaller. The gap appeared when complexity increased.
| Query type | Super | Claude + MCPs | Claude + Super |
|---|---|---|---|
| Simple lookup (11 Qs) | 3.91 / 4 | 3.09 / 4 | 3.36 / 4 |
| Broad knowledge (4 Qs) | 4.00 / 4 | 2.50 / 4 | 3.50 / 4 |
| Complex synthesis (18 Qs) | 3.39 / 4 | 2.56 / 4 | 2.94 / 4 |
| Data queries (8 Qs) | 3.38 / 4 | 2.12 / 4 | 3.00 / 4 |
On a question about a customer's 360-degree overview, Super returned the deal size, key contacts, usage metrics, and strategic context. Claude with MCPs found half the facts and ran into Attio search errors.
For a question on Jason's achievements question, Claude with MCPs retrieved 10 unrelated Jason contacts from Attio. The signal-to-noise ratio degraded as the number of sources increased, which is the opposite of what you want.
This tracks with what enterprise search benchmarks show more broadly. Scale AI's Agentic Tool Use leaderboard and Aisera's CLASSic framework both evaluate AI agents on multi-tool tasks, and both find that accuracy degrades as tool count increases.
The agent must decide tooling, query formulation, and reconciling conflicting results.
A purpose-built retrieval system doesn't face this issue because the orchestration logic is pre-existing rather than improvised by the model at inference time on every query.
An interesting finding from the hybrid: Claude + Super MCP
This was the most interesting configuration to us. Claude using Super as its single data source instead of five separate MCPs.
It landed in the middle on speed, faster than Claude with individual MCPs, slower than Super on its own. Which makes sense: you still have the overhead of Claude's reasoning loop, but you skip the serial tool-calling across multiple integrations.
Where it got interesting was accuracy. On some queries, Claude's reasoning on top of Super's retrieval produced answers that were structured differently, sometimes more analytical, than Super alone. The changelog task was a good example. Claude added context and formatting that made the output more immediately useful.
This hybrid setup was the most thought-provoking result of the whole test. If Super handles retrieval and Claude handles reasoning, you get the reliability of purpose-built search with the analytical depth of a general-purpose model. We're biased, obviously, but we think this is where things are heading.
Where each approach shines
Claude with MCPs has a few strengths:
- Reasoning depth: Once Claude had the right information, its analysis was sharp. It didn't just find data, it interpreted it. The changelog task produced well-structured, contextualized output.
- Conversational flexibility: You can ask follow-ups, change the angle, have it reformat. It's a conversation, not a search query. That matters for exploratory work where you don't know exactly what you're looking for yet.
- No additional cost: If you already pay for Claude, the MCP route costs nothing extra beyond setup time. For a small team, that's a real consideration.
Super's advantages showed up most clearly when complexity increased:
- Speed under complexity: When questions required pulling from 3-4 sources, the integrated architecture meant no serial tool-calling overhead. One query, all sources, one answer.
- Reliability: No cascade errors, no retries, no "Intercom MCP timed out" moments. It either finds it or tells you it can't.
- Signal-to-noise: Claude with MCPs sometimes returned everything it could find, relevant or not (those 10 unrelated Jason contacts from Attio, for instance)
| Super | Claude + MCPs | Claude + Super | |
|---|---|---|---|
| Accuracy | 3.59 / 4 | 2.61 / 4 | 3.12 / 4 |
| Perfect answers (4/4) | 82.9% | 24.4% | 43.9% |
| Avg response time | 39.5s | 101.9s | 67.8s |
| Failed answers (0/4) | 3 | 5 | 2 |
| Fastest answer (of 41) | 40 | 1 | 0 |
| Best or tied accuracy (of 41) | 35 | 12 | 18 |
| Best for | Speed, reliability, multi-source questions | Open-ended reasoning, follow-up conversations, no extra cost | Structured analysis on top of reliable retrieval |
| Ideal user | Teams needing fast, accurate answers across many tools daily | Individuals already on Claude doing occasional lookups | Teams wanting Claude reasoning depth with reliable search |
Why we're sharing this
We use Claude ourselves. Every day. We built an MCP integration so Claude can use Super as a data source. We're publishing this because teams are making real decisions about how to set up their AI knowledge stack right now, and there's very little honest data out there to help them.
For the specific job of finding and synthesizing company knowledge across scattered tools, a purpose-built engine was faster and more reliable than wiring up individual MCPs. For open-ended reasoning and analysis, Claude's general intelligence is hard to beat. And for some use cases, the combination of both was the most interesting result of all.

Christophe Pasquier
Chris founded Slite in 2017 and has spent the decade since thinking about how teams actually keep track of what they know. He writes about where the category is going next — agentic knowledge management, context graphs, and the parts of knowledge work AI is quietly rewriting. He's been wrong about the future before. Mostly he's been early. Find him @Christophepas on Twitter!
Frequently Asked Questions
Does this benchmark mean MCPs are a bad idea for enterprise retrieval?
No. MCPs are a powerful standard for connecting models to tools. The benchmark shows that MCPs alone are not a retrieval strategy. Serial, agent-driven tool calling across many brittle integrations leads to latency and accuracy issues. For serious enterprise retrieval, you want MCPs plus a purpose-built retrieval layer, not MCPs instead of one.
When is wiring Claude directly to tools via MCPs good enough?
Direct MCP connections are often good enough for small teams, occasional lookups, and low-stakes questions where latency and occasional inaccuracies are acceptable. If you mostly need simple, infrequent queries against a few tools and you already pay for Claude, MCPs can be a pragmatic starting point without extra infrastructure.
Why does accuracy drop as you add more tools for Claude to use?
As you add tools, the model has to decide which tools to call, how to formulate each query, how to handle errors, and how to reconcile conflicting or noisy results. That orchestration is improvised at inference time. Each additional tool increases the decision surface and error modes, which is why benchmarks like Scale AI's Agentic Tool Use and Aisera's CLASSic see accuracy degrade with tool count and task complexity.
Can a future, more capable model eliminate the need for a retrieval engine?
Better models will help, but they won't remove structural issues like serial tool latency, flaky integrations, and the need for consistent orchestration logic. Even with stronger reasoning, you still benefit from parallel retrieval, centralized ranking and filtering, and robust error handling. In practice, more capable models make a good retrieval layer more valuable, because they can do more with high-quality context.
How should teams think about designing their AI knowledge stack based on this?
Start by separating concerns: use a dedicated retrieval layer to aggregate, index, and query your tools, and use models like Claude for reasoning and interaction. Minimize the number of direct tool MCPs the model has to juggle. Favor parallel retrieval over serial agentic tool calls. And evaluate vendors not just on model choice, but on how their retrieval architecture handles latency, relevance, and failure modes at scale.
Ready to supercharge your workflow?
Connect your tools and start getting instant answers.
We've been building solutions for knowledge sharing and better work since 2016.